Distilling the Knowledge in a Neural Network
wangjiawei@mail.ustc.edu.cn 2020.7.27
Distilling the Knowledge in a Neural Network 写在前面IntroductionKnowledge Distillation为什么说Logits是Distillation的特例?
写在前面
这篇论文是Hinton提出知识蒸馏的开山之作,最近知识蒸馏火了起来,涌现了很多知识蒸馏的论文。在阅读后续更先进的技术之前,我还是打算把老爷子提出这个观点的思路捋一下。
Introduction
Hinton老爷子貌似很喜欢用类比的手法,第一句话: Many insects have a larval form that is optimized for extracting energy and nutrients from the environment and a completely different adult form that is optimized for the very different requirements of traveling and reproduction. 就把文章的观点表现得淋漓尽致。知识蒸馏就是先在幼虫状态吸收各种能力、各种养分,然后成年之后换一种形态去迁移和繁殖。 而且老爷子指出:A conceptual block that may have prevented more investigation of this very promising approach is that we tend to identify the knowledge in a trained model with the learned parameter values and this makes it hard to see how we can change the form of the model but keep the same knowledge. 所以在这种概念下我们很难在改变模型的基础上保存知识的信息。但是我们应该将 知识(Knowledge) 的概念更加抽象化,就是学习如何从输入向量映射到输出向量。正常的模型学习到的就是在正确的类别上得到最大的概率,但是不正确的分类上也会得到一些概率尽管有时这些概率很小,但是在这些不正确的分类中,有一些分类的可能性仍然是其他类别的很多倍。对这些非正确类别的预测概率也能反应模型的泛化能力。例如,一辆宝马车的图片,只有很小的概率被误识别成垃圾车,但是被识别成垃圾车的概率还是比错误识别成胡萝卜的概率高很多倍。
Knowledge Distillation
知识蒸馏的部分思想借鉴于前几天读的论文DO DEEP NETS REALLY NEED TO BE DEEP?的作者在06年发表的Model compression,这篇论文提出如何把一个深的模型的能力迁移到浅网络模型上,使用的主要的方法是:先在深度模型上用大规模数据集训练,然后把输出用于浅度模型的Target(Soft Target),不过这里不是用Softmax,而是用计算Softmax之前的Logit。而知识蒸馏是一个更广泛的方法,可以证明Logit是其一个特例。主要是提出了一个蒸馏温度的概念,蒸馏温度T是一个hyper parameter,蒸馏后的Softmax如下
下面是在(-10,10)之间随机取多个点然后在 不同的 T 值下绘制的图像。[摘自https://zhuanlan.zhihu.com/p/51550142]
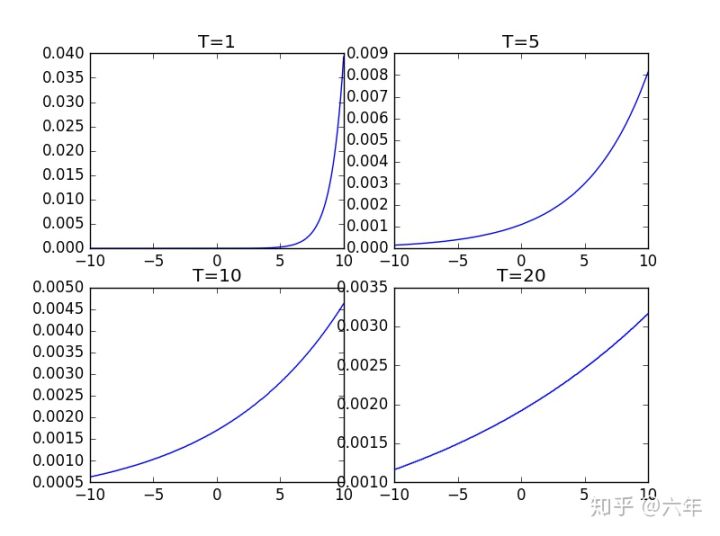
可以看到T增大,函数图像会越来越平滑,那么模型输出的结果不会出现只有一个概率非常大,其余非常小的情况。Distillation主要就是在Soften模型输出结果。

具体蒸馏结构如下:
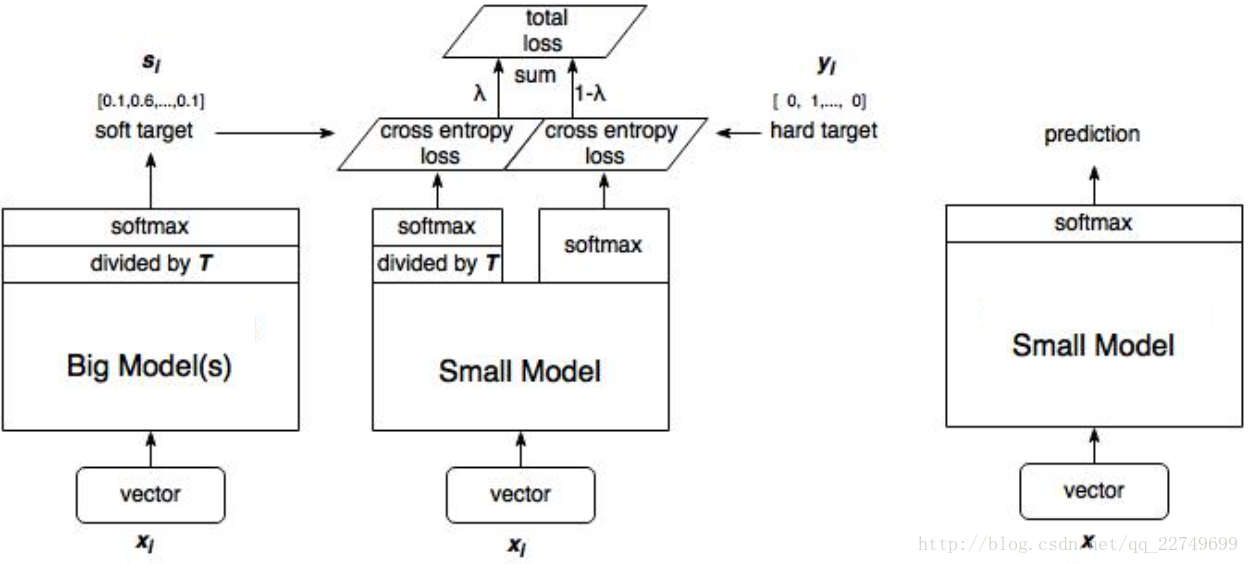
假设你是每次都是进行负重登山,虽然过程很辛苦,但是当有一天你取下负重,正常的登山的时候,你就会变得非常轻松,可以比别人登得高登得远。我们知道对于一个复杂网络来说往往能够得到很好的分类效果,错误的概率比正确的概率会小很多很多,但是对于一个小网络来说它是无法学成这个效果的。我们为了去帮助小网络进行学习,就在小网络的softmax加一个T参数,加上这个T参数以后错误分类再经过softmax以后输出会变大,同样的正确分类会变小。这就人为的加大了训练的难度,一旦将T重新设置为1,分类结果会非常的接近于大网络的分类效果。
为什么说Logits是Distillation的特例?
这个可以简单推导出来:
对(3)中进行求导,可以得出
当T非常大时()
所以
当假设logits时zero—means时, ,所以
而对于Caruana提出的Logits平方误差作为Loss Function,我们可以看到
这里T相当于上面的N,用替代,用替代,求导可得
证毕